Методы декомпозиции звукового сигнала
Опубликовано в сборнике научных статей "Молодёжь третьего тысячелетия" (XLI), c. 833
И.Д. Сиганов
2017.04.24
Аннотация
В статье рассмотрен метод подавления фонового звука статистическими методами, для получения чистого полезного звука. Данный подход отличается от классических алгоритмов фильтрации и не использует анализ спектра звука, так как это не целесообразно в условии полного наложения спектров сигналов. Описанный методы был опробован на примере, в котором из звуковой дорожки аудиозаписи был полностью подавлен фоновый звук.
Ключевые слова: анализ независимых компонент, декомпозиция звука, coctail party problem, цифровая обработка, слепое разделение сигнала
Рассмотрим следующую проблему: как можно максимально сильно подавить определенный фоновый звук в аудиозаписи не исказив полезный сигнал без знания конфигурации микрофонов и окружения? Решение этой проблемы может найти применение в следующих задачах: удалении фоновой музыки защищенной авторскими правами из записей на таких сервисах как YouTube или Twitch и подобных; улучшение существующих систем шумоподавления; ручное управление «слоями» звуковых сигналов в аудиозаписях; улучшение алгоритмов сжатия, так как можно будет применять специфические алгоритмы сжатия на каждый «слой» звука. Стоит сразу отметить некоторые ключевые особенности этой проблемы, чтобы показать, что она не решается классическими широко применяемыми методами фильтрации частот, формирования диаграмм направленности и так далее. Во-первых, фоновый звук далеко не всегда можно вычесть удалением некоторой полосы частот, а в нашем случае, частоты всегда будут перекрываться между фоном и полезным сигналом. Во-вторых, мы не знаем никаких априорных сведений, о том сколько микрофоном участвовало в записи, где они располагались, в каком пространстве была запись, а всё что есть – это только готовая запись звука. В-третьих, мы хотим вносить как можно меньше искажений в полезный сигнал, а фильтрация может приводить к потере части информации и к ухудшению звука.
Одним из методов, который удовлетворяет этим критериям может стать статистический алгоритм ICA – анализ независимых компонент. Он базируется на предположении, что все сигналы статистически независимы и имеют неизвестное негауссово распределение. Из этого следует, что суммарная композиция сигналов стремится к гауссову распределению, а механизм разделения сигналов будет сводиться к уменьшению схожести сигналов с нормальным распределением.
Непосредственное применение метода ICA к реальным данным весьма затруднено существованием аддитивного шума, реверберации и тем фактом, что реальные звуки не обязательно являются статистически независимыми.
Рассмотрим детальнее задачу о подавлении фоновой музыки. Предлагаются следующие гипотезы: фоновый звук известен; смешивание фоновой музыки и полезного звука было сделано синтетически на компьютере простым сведением дорожек, что исключает эффекты реверберации. Тогда можно выделить такие проблемы: как определить какая конкретно музыка играет в фоне; как определить точно моменты времени, когда начинает играть определенный фоновый звук; как вычесть эталон фона из записи. Первая проблема решается алгоритмами идентификации звука по его отпечатку. Сервисы типа Shazam, Goolge music уже решают эту задачу очень эффективно. Вторую и третью проблему можно определить через задачу синхронизации дорожек.
Пусть существует два сигнала и . Возможны следующие случаи:
- Смещения на отсчетов:
- Разные масштабы :
- Комбинация смещения и разности масштабов:
- Растягивание сигнала на l:
- Другие сложные искажения сигналов
В нашем случае имеем: , где – некоторый оператор смещения-искажения, – наблюдаемый сигнал, – это полезный сигнал, – слышимый фоновый сигнал, – исходный фоновый сигнал. Исходя из первоначальной гипотезы о знании , необходимо найти и , что сводится к поиску оператора .
С помощью метода ICA можно найти этот оператор для 2-го случая. Для поиска смещения предлагается воспользоваться полным перебором в лоб, но остается вопрос, что использовать как критерий нахождения верного ?
Одна из реализаций метода ICA использует коэффициент эксцесса как меру непохожести распределения сигнала на нормальное распределение. Напомним, что этот коэффициент эксцесса имеет следующую формулу и принимает значение 0 для нормального распределения.
Учитывая, что полезные сигналы не похожи на нормальное распределение, а из центральной предельной теоремы сумма независимых случайных величин стремится к нормальному распределению, то предположим, что сумма коэффициентов эксцесса при правильно найденном будет больше, чем их же сумма при ложном . Интуитивно, при верно найденном сигналы вычисленные с помощью метода ICA будут полезными, тем самым будут меньше похожи на нормальное распределение, чем ложно найденные сигналы при неверном . Автор отдаёт себе отчёт, что сформулированная гипотеза не более чем интуитивное предположение проверенное эмпирически на нескольких опытах, необходимо будет аккуратно провести доказательство этого утверждения позже.
Далее предлагается ознакомиться с результатами эксперимента по удалению фоновой музыки из звука. Опыт проводился как на синтетических данных, так и на реальной звуковой дорожке, загруженной с YouTube.
Алгоритм по поиску смещения следующий:
- Фиксируем окно в m отсчетов в оригинальном фоновом звуке.
- Смещаем окна на один отсчет и применяем алгоритм ICA на двух сигналах – оригинальном фоне и принятом сигнале . Получаем и .
- Вычисляем и сохраняем эксцессы каждого из полученных сигналов.
- Повторяем шаги 1-3 по всему исходному звуковому файлу.
- Строим график коэффициентов эксцесса и ищем аномалию – резкий пик на фоне общего плато. В этом пике и будет отражен момент правильного обнаружения и .
В синтетическом тесте была взята аудиозапись, где говорили два человека; поверх этого звука была наложена музыка со словами и смещена на 50 отсчетов от начала звукового файла. Частота дискретизации звука 16 кГц, общая длительность звука 180 секунд. Окно поиска было 15 секунд.
 Рис. 1. График суммы коэффициентов эксцесса сигналов на синтетическом тесте.
Рис. 1. График суммы коэффициентов эксцесса сигналов на синтетическом тесте.
В тесте на реальных данных был взят звуковой файл с частотой дискретизации 16кГц длительностью 480 секунд, в котором на фоне играла известная музыка без голоса общей длительностью 230 секунд. Окно было 15 секунд. В результате эксперимента удалось успешно подавить фоновую музыку.
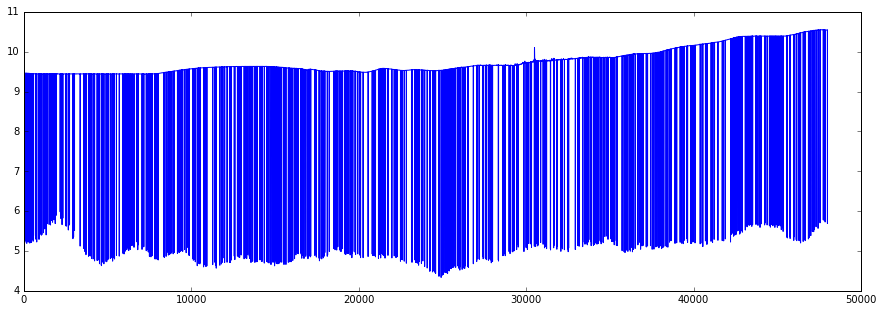 Рис. 2. График суммы коэффициентов эксцесса сигналов на реальном тесте.
Рис. 2. График суммы коэффициентов эксцесса сигналов на реальном тесте.
В заключение стоит отметить, что у данного подхода есть некоторые недостатки и точки улучшения. Как минимум стоит доказать утверждение о метрике успешного нахождения шага смещения. Необходимо исследовать способы ускорения поиска и возможности отказа от полого перебора отсчетов, так как для последнего эксперимента было затрачено 5 часов вычислений для 8-ми минутной записи. Кроме того, описанный подход всё ещё не обрабатывает случаи искажения фонового звука в смысле растяжения, что вероятно будет случаться при перекодировании форматов звука.
Список литературы:
- Hyvärinen A. Independent component analysis. // Philosophical transactions of the royal society. 2013.
- Nicolas Mitianoudis. Audio source separation using ICA. University of London 2004.
- Pierre Comon. Independent component analysis. A new concept? // Signal processing. 1994. Вып. 3.
Sound source decomposition methods
I.D. Siganov
Abstract
In the article was described an approach to suppress background sound by stochastic methods. This method despite the common filter algorithms doesn’t utilize a spectral representation of sound because two sounds actually overlap the spectrum, thus it would be useless at all. The described method was successfully tested on some real dataset, so from the audio track the music was subtracted and payload was obtained.
Keywords: independent component analysis, sound source decomposition, coctail party problem, blind source separation