Наивное применение свёрточного автоэнкодера для фильтрации шумов в звуке
И.Д. Сиганов
2017.12.01
Аннотация
В статье предлагается рассмотреть использование глубокий сверточный автоэнкодер для фильтрации шумов в звуке с речью. Было рассмотрено наивное применение автоэнкодера над изображениями спектров звуков. Хотя эта задача решается классическими методами полосовых и адаптивных фильтров, использование нейросетей может расширить применение фильтров для удаления не только шумов, но и определенных звуков. Таким образом дальнейшее развитие этот подход найдет в сегментации звука, когда для каждого типа звука будет обучаться отдельная модель.
Ключевые слова: свёрточная нейронная сеть, автоэнкодер, фильтрация шумов, сегментация звука, слепое разделение сигнала
Введение
Автоэнкодеры – это нейронные сети прямого распространения, работающие на неразмеченных данных, задача которых состоит в восстановлении некоторого входного сигнала. В процессе обучения сеть пытается найти аппроксимацию некоторой функции идентичности . Эта функция идентичности кажется весьма простой, но на сеть накладывают сильные ограничения, например, делая скрытый слой во много раз меньше входного. Таким образом сеть не может передать неизменно всю информацию от входа сети к выходу. Но благодаря этому нейросеть приобретает интересную особенность – она ищет наиболее важные признаки в данных, стараясь передать их неизменно, но теряя при этом неважные. В случае с передачей звука, мы надеемся, что сеть научится терять информацию о шуме, оставляя только полезный сигнал. Такой подход уже использовался для построения нейросетей, удаляющих шумы с изображений[5].
Методология
В эксперименте использовался небольшой датасет Noizeus, состоящий из 30 двухсекундных записей речи разных людей в 10 различных окружениях (улица, аэропорт, поезд и т.д.). Все звуковые файлы были преобразованы в изображения спектров. Во время обучения на вход автоэнкодера подавались изображения спектра зашумленных сигналов, а на выход – изображения спектра чистых сигналов. Таким образом нейросеть училась пропускать через себя изображение и удалять шумы из него. Предполагалось, что шумы в изображении спектра и есть шумы в звуке. После обучения проходила фаза контроля на отложенном датасете, при котором пропущенные через автоэнкодер спектрограммы были восстановлены обратно в звук и прослушаны асессором.
Модель
Автоэнкодер состоит из двух частей – кодера , переводящего входной сигнал в некоторый сжатый код, и декодера , который по коду восстанавливает сигнал. Во время обучения происходит минимизация некоторой функции потерь . В данной работе использовался автоэнкодер, построенный на основе глубокой свёрточной нейросети. Размерность входного слоя 128x128. Кодировщик состоял из 3 сегментов, в каждом из которых был сверточный слой с размером ядра свёртки 3x3 и шагом 1, слой активации ReLU, слой MaxPooling, понижающий размерность в два раза. Декодер в свою очередь был симметрично зеркален кодировщику, но вместо MaxPooling слоя там использовался Upsampling слой для повышения размерности. В конце сигналы последнего свёрточного слоя декодера проходят через sigmoid функцию. На рисунке 1 изображена схема сети, по которой видно, что сначала изображение сжимается до 16x16 пикселей с 64 фильтрами, потом восстанавливается обратно до 128x128 пикселей с 1 фильтром. Обучение происходило с использованием оптимизатора Adam с коэффициентом скорости обучения 0.001, функция потерь – бинарная кроссэнтропия. Для регуляризации сети использовался dropout 0.2 после каждого сверточного слоя.
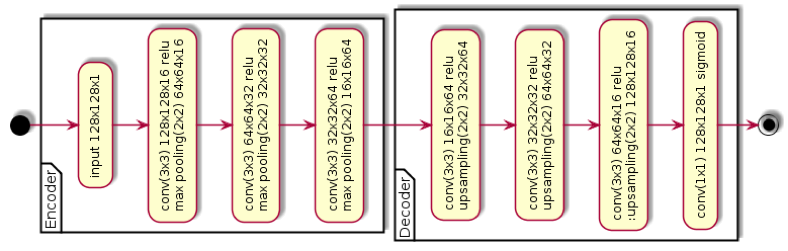 Рис. 1 Архитектура сверточного автоэнкодера
Рис. 1 Архитектура сверточного автоэнкодера
Результаты
На рисунке 2 представлен пример результата работы обученного автоэнкодера, где первое изображение – это спектр 2 секундного семпла чистого звука с частотой дискретизации 8кГц, второе изображение – это зашумленный сигнал шумами аэропорта, а третье изображение – это восстановленный спектр. На каждом изображении по оси X отложено время, а по оси Y – частота. По рисунку видно, что сеть сумела восстановить общие черты изображения спектра. Хотя результат похож на сильное размытие входного изображения, можно заметить интересные детали: явно выражены темные участки спектра, который просто так после размытия не получить, полностью погашены шумы в низких частотах. Но сеть не уловила важную особенность на изображениях спектра – полосы вдоль определенных частот. Вероятно это связанно с тем, что ядра свертки, maxpooling и upsampling слоев были квадратным. Возможно, стоило настроить модель так, чтобы она слабее сжимала информацию вдоль оси Y – оси частот сигнала.
 Рис. 2 Чистая, зашумленная, восстановленная спектрограммы
Рис. 2 Чистая, зашумленная, восстановленная спектрограммы
Заключение
В описанных экспериментах была проверена наивная гипотеза, что возможно очищать звуковой сигнал от шумов, используя автоэнкодер над изображениями спектра сигналов, предполагая, что шумы в изображении спектра связаны с шумами в самом звуке. Несмотря на восстановление формы спектра звука, приемлемого подавления шумов добиться не удалось, как в прочем и качества восстановленного звука. Вероятно, это связано с тем, что поиск шума в спектрограмме, как в изображении, не имеет в себе какого-то физического смысла. Или необходимо собрать большой датасет и делать упор на точное восстановление изображения вдоль оси частот. Так же интересно попробовать применять автоэнкодеры напрямую над сырыми аудио данными. Тогда исчезнет проблема восстановления звука из спектра и алгоритм можно будет использовать в реальном времени на устройствах.
Список литературы
- Goodfellow I., Bengio Y., Courville A. Deep Learning. MIT Press, 2016. 781 p.
- Francois Chollet. Building Autoencoders in Keras. URL: https://blog.keras.io/building-autoencoders-in-keras.html (дата обращения: 12.12.2017)
- Andrew Ng. CS294A Lecture Notes. Sparse autoencoder. Stanford. URL: http://web.stanford.edu/class/cs294a/sparseAutoencoder.pdf (дата обращения: 12.12.2017)
- NOIZEUS: A noisy speech corpus for evaluation of speech enhancement algorithms. URL: http://ecs.utdallas.edu/loizou/speech/noizeus/ (дата обращения 12.12.2017)
- Image Restoration Using Convolutional Auto-encoders with Symmetric Skip Connections. URL: https://arxiv.org/abs/1606.08921 (дата обращения: 12.12.2017)
A naïve approach of applying an autoencoder to denoise sound
I.D. Siganov
Abstract
In the paper the deep convolutional autoencoder is proposed to be used in the problem of denoising speech records. Though this problem usually is solved by applying adaptive or band filters, but using neural network would be useful in the sound segmentation problem. Because an autoencoder could be trained against different types of sound, the model will be able to filter out these types of sounds thus sound separation could be built.
Keywords: convolutional neural network, autoencoder, sound denoising, sound segmentation, blind source separation